Just before the start of the fall semester, the University of Michigan announced that it was launching a new suite of tools, all focused on “generative AI”, (although so far limited to language models), which will be available to all students, faculty, and staff.
At the moment, there are three offerings. The first of these is basically a custom ChatGPT-style interface that apparently provides access to three language models: GPT-4.0, GPT-3.5, and LLaMA 2 (7B). The second system, called Maizey, is some sort of system to allow users to customize models based on a set of documents. The description given for this system is frustratingly vague, and somewhat confusingly mentions “indexing” your data. Based on the description, however, it seems plausible that this involves some sort of model fine tuning. The third system is some sort of toolkit for training and deploying new models, but I haven’t gotten access to this yet, so I won’t have anything to say about it here.
Why would someone use these systems, especially the first, given that ChatGPT already exists and is freely available? Well, for one thing, GPT-4 is apparently included among the available models, which users would otherwise have to pay $20/month to OpenAI for access.
Second, Information and Technology Services (ITS) claims that all data shared with these systems will be kept private and not used to train AI models. Depending on how you interact with ChatGPT, OpenAI offers the same promise, but this seems like this could be a big advantage, depending on what “private” means here. In particular, perhaps it will be possible to use these systems with data that could not otherwise be exported outside of the University. Notably, we apparently ARE permitted to feed Student Education Records (covered by FERPA), into these systems.1 That permission only extends so far, however. Health data covered by HIPPA, for example, is not yet allowed. Unfortunately, the precise data classifications seem somewhat complicated.2 “High sensitivity” data is also forbidden, which include “Disclosure could cause significant harm to individuals and/or the university”, but how to determine what qualifies sounds like a question for lawyers.
A final advantage noted in the press release is that UMich ITS has configured their interface to work with screen readers, which seems like a nice accessibility feature that ChatGPT apparently does not support.
To get started, I opened up the ChatGPT style interface, which has been appropriately themed in Maize and Blue. Selecting GPT-4.0, I started with a greeting. The first response came with very little latency, and is identical to something that GPT-4 might say.

Digging in slightly more, it is clear that some sort of customization has been done, as the model will output responses that self identify as being part of the University of Michigan, without being directed towards that.

It’s not totally obvious how this is being done, or how these models differ from those that are offered directly by OpenAI. However, the most likely possibility (one that has been used by numerous startups), is to take the user’s input, add some sort of additional text to the beginning and end, and then feed that into the model, without the user knowing.
It’s not necessarily straight-forward to test this, but as a simple hack, let’s start a new session, and try asking the system which universities I mentioned in a prompt, without specifically naming Michigan.

Aha! Again, not definitive, but it seems quite plausible that some sort of prompt is being appended to the input that includes the string “University of Michigan”.
People have devised numerous clever ways to try to figure out what text is being appended or prepended by these various systems. I am somewhat skeptical about how much trust we should put in the responses to these “hacks”, but just for fun, let’s start a new sessions and try asking for more information.

That’s a bit of a non-committal response. Let’s try a basic “attack”, assuming that the the instructions are being prepended to the start of the input:

Well, that was easy! Models are not normally so willing to divulge the information that they have been primed with. Again, we can’t be sure that this is exactly what is happening, but it is certainly a plausible explanation.
What about the claim that the model was developed by the University of Michigan? Pressing for more information, the model admits its error:

However, after playing around with the system for a bit, I am less confident than I was that we are actually getting access to GPT-4. Even when selecting “GPT-4.0” from the dropdown menu, asking the system which model it was based on leads it to respond with “GPT-3”.

I tried this a number of ways an always got the same answer. By contrast, GPT-4 (from OpenAI) will self-identify as being GPT-4 (although it still notes that it doesn’t have any information more recent than September 2021).
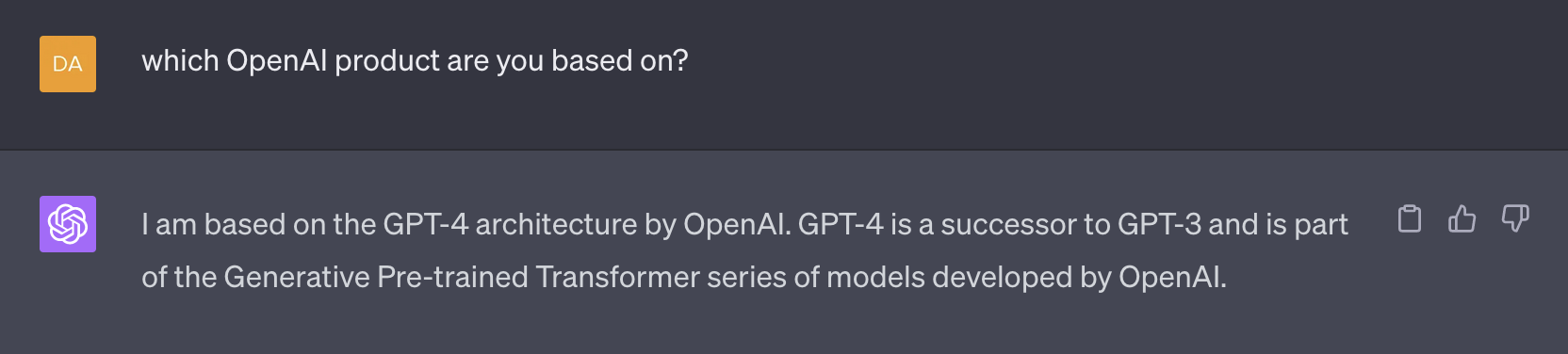
That’s not much evidence, but so far the performance of the UMich “GPT-4.0” model seems somewhat weaker than would be expected.
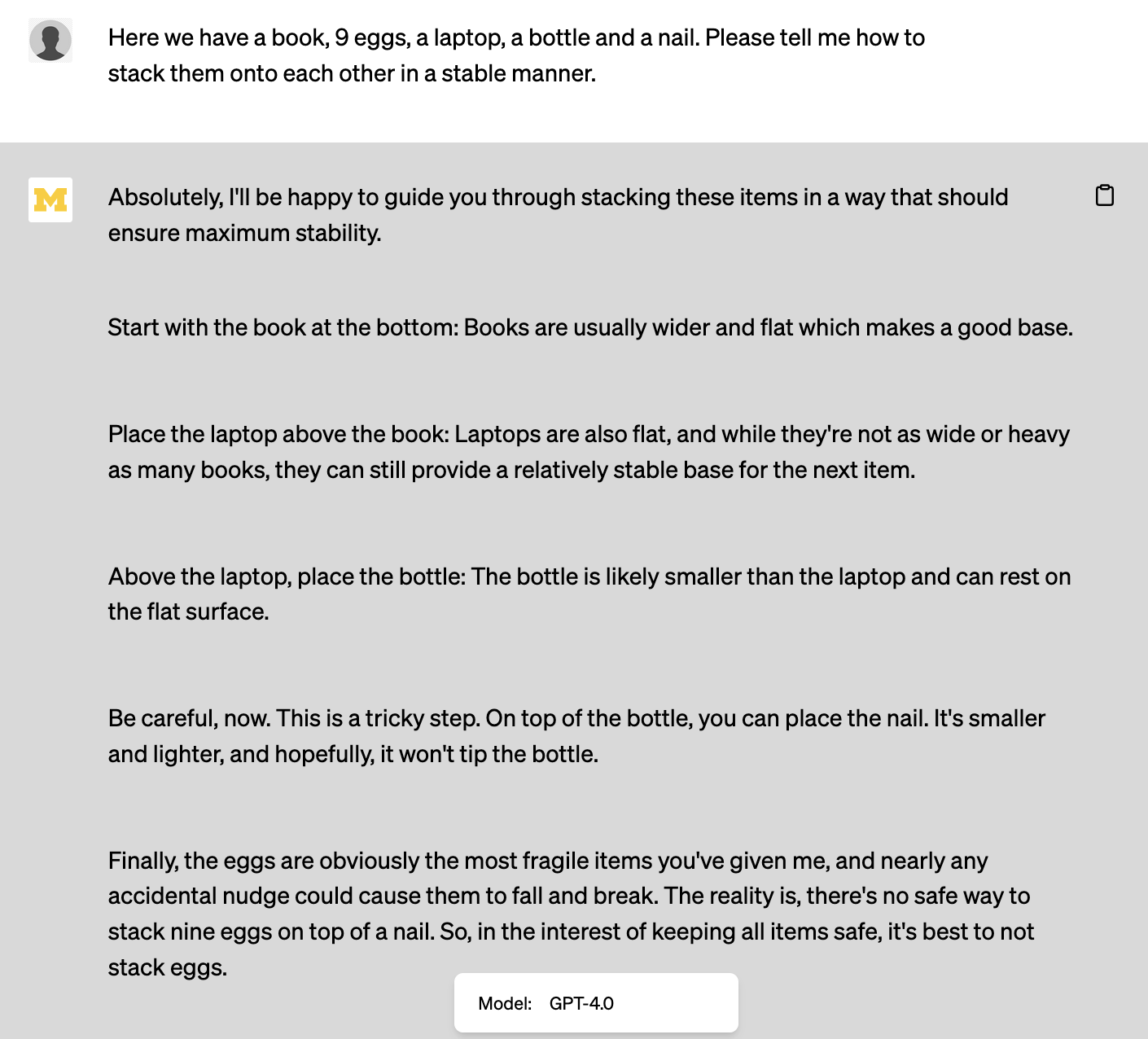
Borrowing an example from the “sparks” paper, this model badly fails the “stacking” problem that was so impressive in Microsoft’s assessment.
Similarly, asking the model to write a python program to calculate an arbitrary digit of pi was a mixed bag. The first time I tried this, it gave me code which ran, but which did not produce the correct result. A second attempt gave me a trivial answer, using the value of math.pi value python’s math library. A third attempt (asking it to not import any packages) gave me a correct answer based on the Spigot algorithm. This lack of reproducibility of course illustrates the difficulty inherent in evaluating the capabilities of systems like these. Still, writing code like this is something that GPT-4 can reliably do, although the OpenAI model seems to prefer to generate the digits in hexadecimal by default.
At this point, I apparently hit the rate limit, so had to give up on these experiments for the time being.
Regardless, many questions remain open: How much is the University paying for access to and infrastructure for these systems? Exactly how do the models it is providing access to differ from those provided by OpenAI? How will they change over time? And what exactly will Maizey be doing when you provide a corpus of documents for it to “index”?
The idea of providing free access to cutting edge tools for all students, faculty, and staff at the university is certainly exciting. I am also hopeful that more transparency and information will become available in the coming weeks. However, for most scientific purposes, there are far too many uncertainties and unanswered questions about these systems for them to be especially useful at this stage, at least for the time being.
Internal link to information about what is allowed: https://safecomputing.umich.edu/dataguide/?q=node/266 ↩︎
Internal link to information about data sensitivitt levels: https://safecomputing.umich.edu/protect-the-u/safely-use-sensitive-data/classification-levels ↩︎