Despite their limitations, off-the-shelf models are still quite widely used by computational social science researchers for measuring various properties of text, including both lexicons, like LIWC, and cloud-based APIs, like Perspective API.
The approach of using an off-the-shelf model has some definite advantages, including standardization and reproducibility, but such models may not be reliable when applied to a domain that differs from the ones on which they were developed.
Demonstrating validity in the application domain is especially important (by comparing to a more reliable instrument, like human annotations), but it seems like we should also be able to do better by adapting to the target domain. Unfortunately, most domain adaptation techniques assume access to the source data or the full model, which we may not have, especially when working with commercial lexicons or cloud-based APIs.
In a new paper to appear in the Findings of ACL (2022), written by Junshen K. Chen, Dan Jurafsky, and myself, we propose treating domain adaptation as a modular problem, involving both model producers and model consumers, practicing a kind of independent cooperation. In particular, we suggest that model producers should strive to facilitate domain adaptation by model consumers, even if they are not able to share the training data (perhaps due to reasons related to privacy or copyright).
In particular, we assume that model producers will train a linear or contextual embedding model on one or more domains, and release it for use by model consumers without accompanying source data. Model consumers, by contrast, will want to apply an existing model, adapting it to a new domain (while also evaluating reliability in that domain) using a minimal amount of labeled data and computational resources.
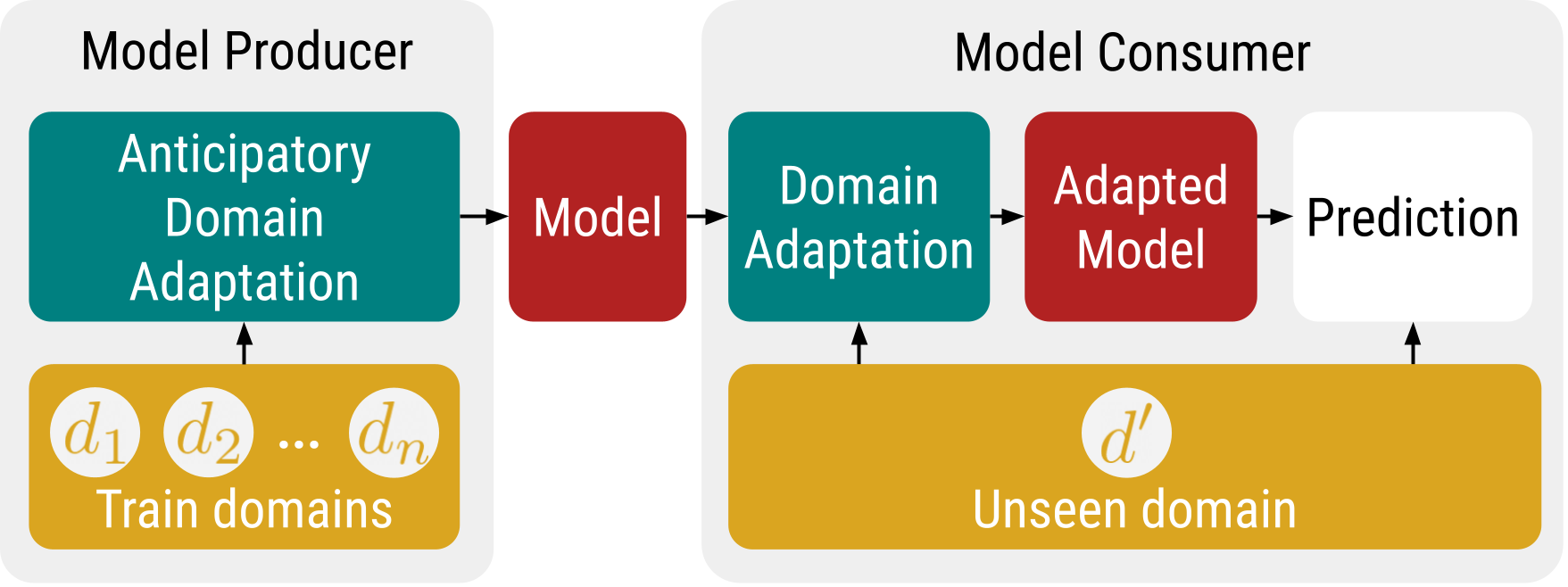
Schematic diagram for modular domain adaptation
In the paper, we propose two lightweight techniques that work for this purpose. For the first, DsBias, the model producer replaces the overall learned bias term in the model with a term equal to the log of the label frequencies in each training domain (similar to SAGE). To adapt the model, the model consumer can then plug in an appropriate label distribution for their application domain, either based on prior expectations or a small amount of labeled data.
The second technique, DsNorm, is specific to linear models, and normalizes each feature by its frequency in each training domain. The equivalent normalization can then be applied by model consumers based purely on unlabeled data from the new domain.
As weak and strong baselines, we compare these against the accuracy rates for i) predicting the most common class, and ii) traditional domain fine-tuning (DFT) for RoBERTa, which assumes access to the model and sufficient computational resources for continued training.
On four different text classification datasets, each involving 5 or more domains (e.g., news issues or product categories), we find DsNorm and DsBias lead to better out-of-domain performance when used with either linear or contextual embedding models.
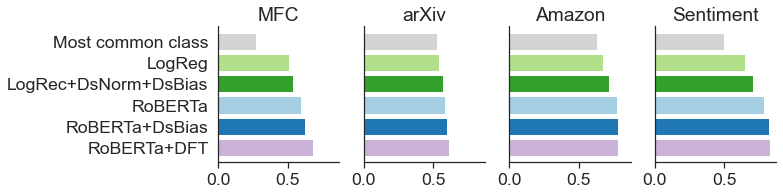
Average out-of-domain accuracy of various methods on four multi-domain datasets
Unsurprisingly, the contextual embeddings models perform much better than the linear models, even without adaptation. We also found that the average drop in accuracy when applying the baseline models to new domains was between 3–10%, emphasizing the need to both adapt and validate off-the-shelf models when applying them to new domains.

Average performance drop of baseline models when going from in-domain to out-of-domain data
As a further way to validate the performance of our linear models, we also compared the baseline out-of-domain accuracy on our sentiment analysis datasets against several off-the-shelf sentiment lexicons.
Two things emerged from this: first, without tuning or adaptation, there were relatively small differences in out-of-domain accuracy among the various lexicons, including VADER, LIWC, and Stone’s General Inquirer from 1962. Second, when applying DsNorm and DsBias, our adapted logistic regression model had slightly higher out-of-domain accuracy, on average, than any of the lexicons, even when tuned to the target domain.
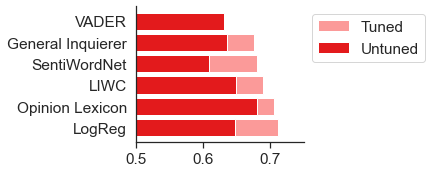
Comparing logistic regression (with and without DsNorm and DsBias) to various off-the-shelf lexicons
For contextual embedding models (RoBERTa), it remains the case that traditional domain fine-tuning (i.e., continuing to train on a small number of labeled samples from the target domain) was the most effective method of domain adaptation. However, doing so requires access to the full model, along with sufficient computational resources, (GPUs), which may not be readily available to all researchers.
The question also arises with fine-tuning of how much data to use for adaptation and how much for evaluation; by contrast, DsBias does not require any additional training, and thus any available labeled data can more easily be used for both estimating performance and adaptation, by applying two-fold sample splitting, as we show in the paper.
In summary, here are the main takeaways from this work:
- Although linear models may still be preferred for reasons of simplicity, interpretability, or minimizing bias, contextual embedding models had much higher out-of-domain accuracy on all the tasks we considered; thus, the computational social science community would benefit greatly if model developers would release both linear and contextual embedding models when they are unable to share their training data.
- By using the kinds of modular domain adaptation techniques we propose in the paper, model developers can facilitate domain adaptation by model consumers, thereby enabling more accurate measurements in new domains, and we hope that this work will encourage the development of other techniques that work for this kind of modular setup.
- Domain fine-tuning remains a highly effective way to do domain adaptation with a small amount of labeled data, but may not be a possibility when working with commercial models or cloud-based APIs.
- The accuracies of a variety of sentiment lexicons (both historical and contemporary) were surprisingly similar on a variety of sentiment analysis datasets; even when tuning to the application domain, none did better in terms of out-of-domain accuracy than a basic bag-of-words logistic regression model deployed in combination with our lightweight adaptation techniques.
- In the end, transparency is hugely beneficial, and we strongly encourage model developers to release both the code and data for their models whenever possible, both for reproducibility, and to enable more powerful domain adaptation techniques.
All code for the paper is online, and we also release both linear and contextual embedding classifiers for predicting framing, based on the Media Frames Corpus.